Monitoring Survey - Environments
In the last posts I’ve talked about the use of metrics, the primary tool people used in monitoring and the demographics of the survey.
In this post I am going to look at the questions around what parts of people’s environments are monitored and when checks are added to your environment.
As I’ve mentioned in previous posts, the survey got 1,016 responses of which 866 were complete and my analysis only includes complete responses.
This post will cover the questions:
8. What parts of your environment do you monitor? Please select all the apply.9. When do you most commonly add monitoring checks or graphs to your environment?What parts of your environment do you monitor?
With Question 8 I was most interested in understanding what types of infrastructure is monitored. Traditionally, monitoring has been an operational function focused on server and network infrastructure. This is reflected in the classic trio of monitored elements: CPU, Disk and Memory and with a shout-out to their close cousin the ICMP-based ping check. Monitoring, in a lot of organizations has had a limited interest in covering applications and their logic and its use for testing business logic has been even more rare.
I divided monitoring types into:
- Server Infrastructure
- Network Infrastructure
- Application logic
- Business logic
I also added a catch-all for anyone whose skip logic didn’t move them past this question.
I’ve compiled the results into a summary table.
| Environments Monitored | % |
|---|---|
| Server Infrastructure | 95% |
| Application logic | 67% |
| Network Infrastructure | 66% |
| Business logic | 32% |
| We don’t monitor anything | 0% |
As expected 95% of respondents conducted Server Infrastructure monitoring. A smaller 66% of respondents also use monitoring for Network Infrastructure. I had expected a higher percentage here but the result may be related to the siloing of network management in many organizations into a Network-specific team. There may also be a selection bias.
Most interesting though is the 67% of respondents who are monitoring Application logic. This is more than I expected and is pretty exciting to see. Even the, much smaller, 32% who monitor business logic is also an encouraging sign that monitoring purpose may be maturing.
When do you add checks?
Question 9 focused on when respondents most often deployed monitoring to their environments. Here I was most interested in measuring how reactive monitoring environments are within organizations. Many organizations build a baseline or limited collection of monitoring checks when infrastructure is built or when applications are deployed. Alternatively, adding monitoring checks is an action generated from a postmortem or incident. I was hoping this question would shed light on whether organizations focused on building up-front and high quality monitoring or built more piecemeal systems in response to changing conditions or incidents in the environment.
I don’t think the question was perfect and when I run the survey again I’ll refine this question to make the intent more clear and seek a broader understanding of how initial monitoring is applied versus any reactive monitoring that might be implemented later.
Respondents had the option of selecting:
- When we build new infrastructure or deploy new applications, or
- When something goes wrong and we want to monitor for that problem in future.
I’ve graphed the data by respondent.
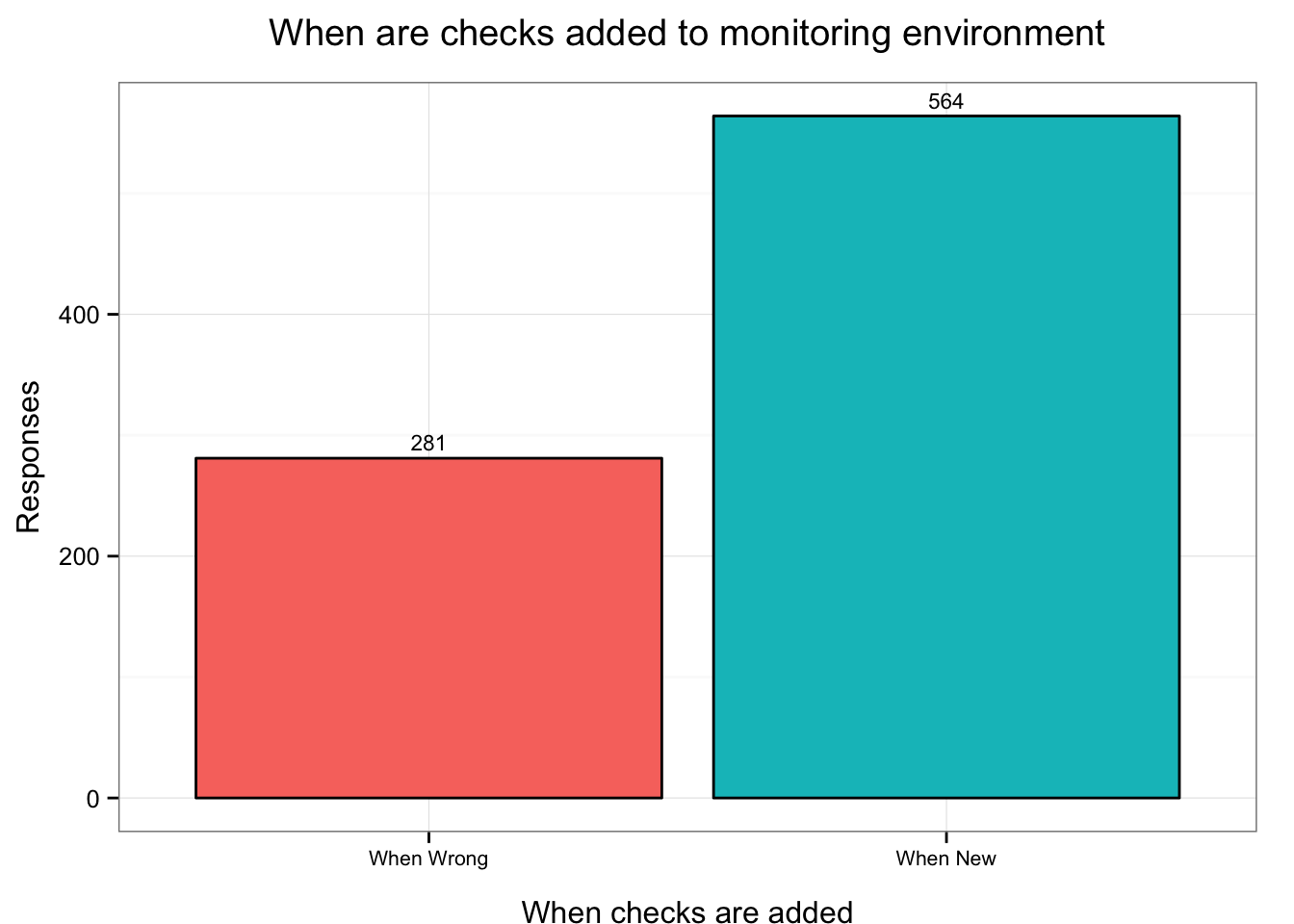
We can see that 564 respondents, or 66.7% of them, add checks when new infrastructure and applications are deployed. In contrast, 281 respondents or 33.3%, most commonly added checks as a response to an incident or outage. That’s higher than I had expected, especially given the demographics and my suspicion of the potential selection bias in the respondents. I had hoped that monitoring was more planned and less ad hoc and reactive.